Equivalence Partitioning – A Complete Guide for Smart Test Case Design
In software testing, one of the biggest challenges testers face is deciding how many test cases are enough. Testing every possible input value is practically impossible in real-world systems. For example, if an input field accepts numbers from 1 to 1,000,000, it is unrealistic to test all one million values. This is where Equivalence Partitioning (EP) becomes a powerful and essential technique.
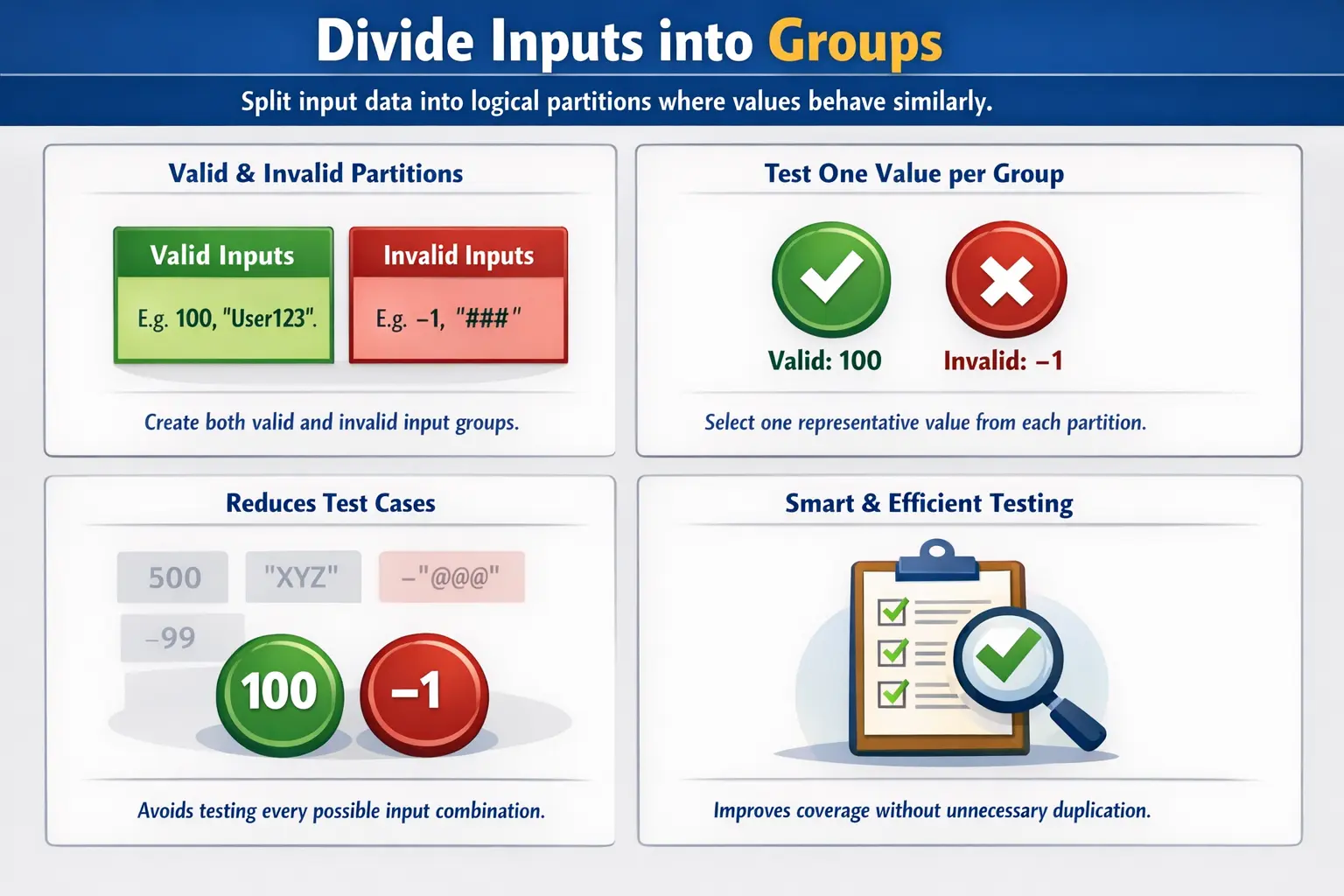
Equivalence Partitioning is one of the most fundamental test case design techniques used in manual and automation testing. It helps testers reduce the number of test cases while maintaining logical and effective coverage.
This article provides a deep understanding of Equivalence Partitioning, including its purpose, types, steps, examples, common mistakes, and interview relevance.
1. Definition of Equivalence Partitioning
Equivalence Partitioning (EP) is a test case design technique where input data is divided into logical groups, called partitions, such that all values within a partition are expected to behave the same way.
In simpler terms, instead of testing every possible value, we group similar inputs together and test just one representative value from each group.
Equivalence Partitioning answers the key question: “Which inputs can be treated as equivalent?”
If one value from a group works correctly, other values from that same group are assumed to behave similarly.
2. Why Equivalence Partitioning Is Necessary
In real-world applications, input possibilities are often very large. Consider the following examples:
- Age field: 1 to 120
- Password field: 8 to 20 characters
- Salary field: 0 to 10,000,000
- Text field: unlimited characters
Testing all possible values is impossible. Even if technically possible, it would be inefficient and wasteful.
Equivalence Partitioning solves this problem by:
- Reducing the number of test cases
- Eliminating redundant testing
- Increasing efficiency
- Maintaining logical coverage
- Identifying valid and invalid groups
This makes testing smarter, not heavier.
3. Purpose of Equivalence Partitioning
The main objectives of Equivalence Partitioning are:
- To reduce the number of test cases without reducing coverage
- To improve efficiency and save time
- To avoid duplicate or repetitive testing
- To systematically identify valid and invalid input groups
- To ensure structured testing instead of random testing
Equivalence Partitioning is about optimization. It ensures that each test case adds value.
4. Types of Equivalence Partitions
Equivalence partitions are divided into two primary types:
1. Valid Equivalence Partition
This includes input values that satisfy the requirement. These inputs are expected to be accepted by the system.
2. Invalid Equivalence Partition
This includes input values that do not satisfy the requirement. These inputs are expected to be rejected by the system.
Each partition should be tested using at least one representative value.
5. How to Apply Equivalence Partitioning (Step-by-Step)
Applying Equivalence Partitioning requires structured thinking. Follow these steps:
Step 1: Identify Input Conditions
Understand the requirement clearly. Identify constraints such as range, format, length, type, or business rule.
Step 2: Divide Inputs into Partitions
Split the input space into valid and invalid groups. Each group must contain values that behave similarly.
Step 3: Select Representative Values
Choose one value from each partition to represent that entire group.
Step 4: Design Test Cases
Create test cases using selected representative values. This process ensures logical coverage with minimal effort.
6. Real-Time Example 1: Age Field
Requirement: Age must be between 18 and 60.
Partitions:
- Valid Partition: 18 to 60
- Invalid Partition 1: Less than 18
- Invalid Partition 2: Greater than 60
Representative Test Values:
- 30 (valid)
- 15 (invalid – below range)
- 65 (invalid – above range)
Instead of testing all values from 18 to 60, we test one representative value.
7. Real-Time Example 2: Password Length Validation
Requirement: Password must be between 8 and 12 characters.
Partitions:
- Valid Partition: 8 to 12 characters
- Invalid Partition 1: Less than 8 characters
- Invalid Partition 2: More than 12 characters
Representative Test Values:
- 10 characters (valid)
- 5 characters (invalid)
- 15 characters (invalid)
This ensures complete logical validation without unnecessary duplication.
8. Real-Time Example 3: Dropdown Selection
Requirement: Country field must have one selected value.
Partitions:
- Valid Partition: One valid country selected
- Invalid Partition 1: No selection
- Invalid Partition 2: Invalid selection (if applicable)
Representative Test Cases:
- Select “USA” (valid)
- Leave blank (invalid)
Even dropdowns can use Equivalence Partitioning.
9. Real-Time Example 4: Salary Input Field
Requirement: Salary must be numeric and between 10,000 and 100,000.
Partitions:
- Valid Partition: Numeric values between 10,000 and 100,000
- Invalid Partition 1: Less than 10,000
- Invalid Partition 2: Greater than 100,000
- Invalid Partition 3: Non-numeric values
Representative Values:
- 50,000 (valid)
- 5,000 (invalid)
- 200,000 (invalid)
- “abc” (invalid)
Notice how multiple invalid partitions may exist.
10. Equivalence Partitioning vs Exhaustive Testing
| Aspect | Equivalence Partitioning | Exhaustive Testing |
|---|---|---|
| Number of test cases | Few | Very many |
| Efficiency | High | Low |
| Practicality | Realistic | Impossible |
| Coverage | Logical | Theoretical complete |
Exhaustive testing means testing every possible input combination. In most systems, this is unrealistic.
Equivalence Partitioning offers a balanced and practical alternative.
11. When to Use Equivalence Partitioning
Equivalence Partitioning is highly effective in:
- Numeric input fields
- Text length validations
- Form validations
- Age, salary, percentage, and amount fields
- Dropdown validations
- Business rule validations
- API parameter validation
Whenever inputs can be grouped logically, EP can be applied.
12. Combining EP with Boundary Value Analysis
Equivalence Partitioning is often used together with Boundary Value Analysis (BVA).
Example: Age range: 18–60.
- EP groups values into valid and invalid partitions.
- BVA tests boundary values like 18, 60, 17, and 61.
EP identifies groups. BVA focuses on edges. They complement each other.
13. Common Mistakes in Equivalence Partitioning
Even though EP is simple conceptually, testers often make mistakes.
Mistake 1: Ignoring Invalid Partitions
Testing only valid inputs is incomplete. Invalid partitions must be tested.
Mistake 2: Confusing EP with Boundary Testing
EP groups data logically. Boundary testing specifically targets edge values.
Mistake 3: Assuming One Valid Case Is Always Enough
Sometimes multiple valid partitions exist. Each logical group must be represented.
Mistake 4: Overlooking Data Type Constraints
For example, entering letters in numeric fields forms an invalid partition.
Mistake 5: Not Documenting Partitions Clearly
Poor documentation leads to missed scenarios.
14. Advantages of Equivalence Partitioning
- Reduces test case count
- Saves time and effort
- Increases efficiency
- Maintains structured coverage
- Easy to apply
- Ideal for manual testing
- Useful in automation test design
It is one of the simplest yet most powerful test design techniques.
15. Limitations of Equivalence Partitioning
- Does not specifically test boundary values
- May miss defects at edges if used alone
- Requires good requirement understanding
- Not ideal for complex decision logic (Decision Table is better there)
Therefore, EP should be combined with other techniques when needed.
16. EP in Agile and Real Projects
In Agile projects, time is limited. Testers cannot write hundreds of redundant test cases.
Equivalence Partitioning helps:
- During sprint testing
- During regression suite optimization
- While reducing automation scripts
- While designing API validation scenarios
It ensures fast yet reliable validation.
17. EP in Automation Testing
Equivalence Partitioning is extremely useful when creating data-driven automation tests.
Instead of adding hundreds of test data entries, you add:
- One valid partition value
- Multiple invalid partition values
This keeps automation lean and maintainable.
18. Interview-Ready Answers
Short Answer
Equivalence Partitioning is a test case design technique that divides input data into logical groups, where one representative value is tested from each group.
Detailed Answer
Equivalence Partitioning reduces the number of test cases by grouping inputs that are expected to produce similar outcomes. By selecting one value from each valid and invalid partition, testers achieve logical coverage while minimizing redundancy.
19. Key Takeaway
Equivalence Partitioning is about testing smarter, not testing more.
It allows testers to reduce redundant test cases while ensuring proper validation of both valid and invalid input groups. When applied correctly, it significantly improves efficiency without compromising quality.
A skilled tester does not test every possible value.
A skilled tester identifies logical partitions and tests representative values.
That is the power of Equivalence Partitioning.